Machine Vision for FIRST Robotics: Post-mortem
— 18 March, 2017
Well, a couple of weeks ago was officially the final day of the 2017 FIRST robotics build season. Six weeks of rapid prototyping, assembly, and testing, completed. Our team's robot sealed in a plastic bag and in our closet. It's over. For some team members though, last night represented the culmination much more than just six weeks. Surprisingly, in November of 2015 I found myself working on exactly the same project I just barely finished in time for this year's season to end. Machine vision. Making our robot actually sort of understand its surroundings instead of just driving around deaf, blind, and dumb. Vision on our team has been a long time coming, dating all the way back to the preseason of last year's competition, Stronghold. Here's the story :)
Preseason of Stronghold (2015)
Work first began on vision during the preseason of Stronghold (November-ish maybe?). Our team delegated two programmers to the task: myself (a first-year member of our team), and my dear friend Chris (on his second year). Our first prototypes used Axis IP cameras and processed images in C++ on the roboRIO, using WPIlib. With no one our team with any experience in vision, we were essentially on our own. I'll attempt to summarize what we learned during those first months of prototyping:
-
Images can be represented digitally using a variety of different "color spaces" to store the color of each pixel. For most day-to-day applications, we use the RGB model, where each pixel has a value from 0-255 for each of the primary colors red, green, and blue. Also notable is the HSL model, where each pixel has a value for it's hue, saturation, and lightness.
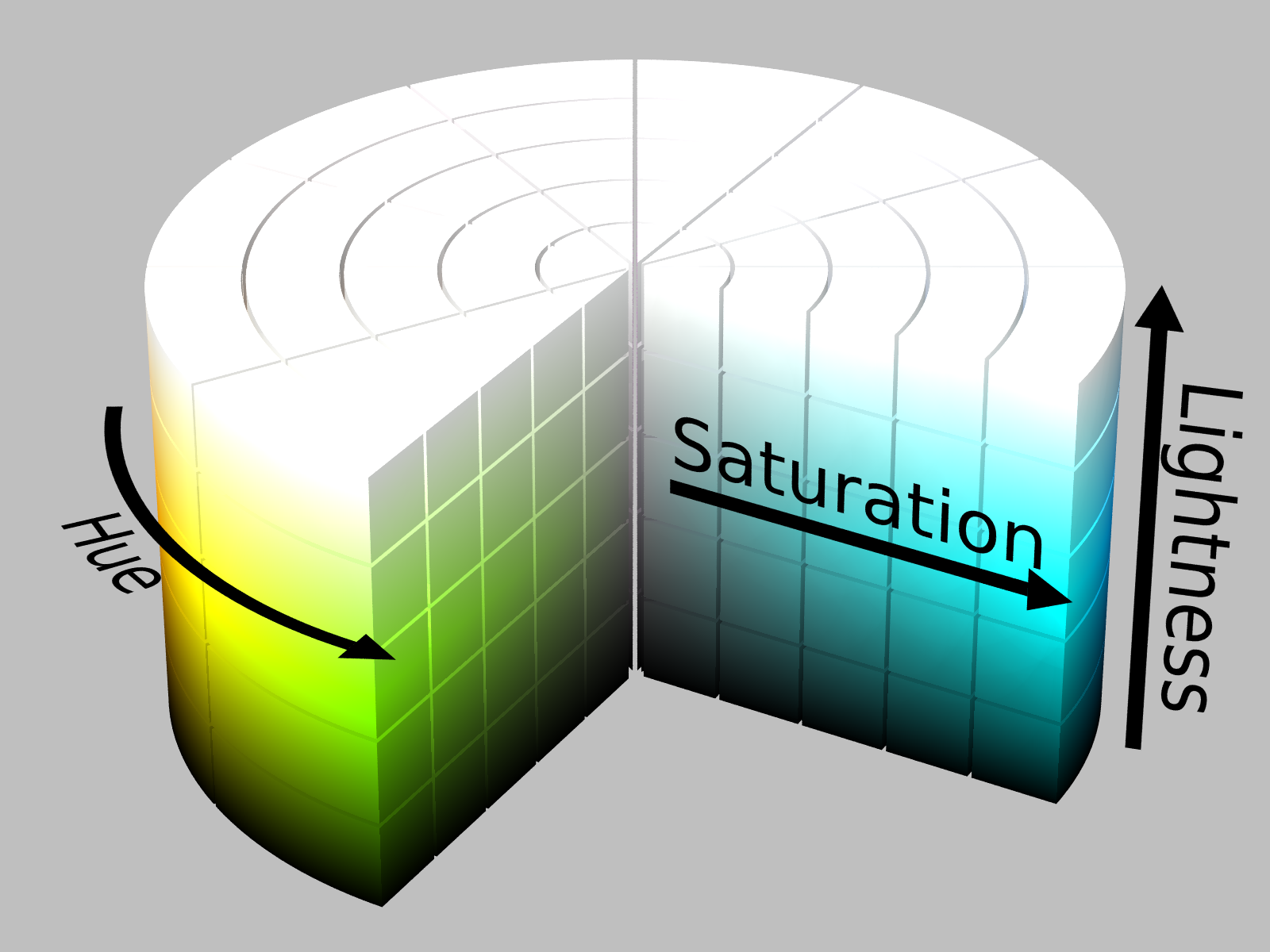 Visualization of the HSL model
Visualization of the HSL model -
Thresholding is a process which converts a gJamesscale image to a binary image, turning a pixel white if its value is greater than or less than (depending on the type of threshold being applied) a constant T, and black otherwise. Many variations on this algorithm exist, for examples ones which set the pixel to be white if it's within a range of values, or which operate on full color images, simply thresholding each color band separately, and performing a bitwise AND on the resultant images. For the purposes of this post, I'll refer to all of these by the simple term "thresholding".
 The result of a thresholding operation
The result of a thresholding operation -
How to retrieve images, convert between color models and perform thresholds using WPIlib.
Using this information, we wrote a program which would attempt to find a green target in front of the camera and decide if it was centered in the frame. Although the actual program was written in C++, I'll just provide some C-like psuedocode, for brevity:
bool isTargetCentered() {
// RGB frame directly from camera
frame = getFrame()
// Convert to HSL to allow us to threshold for green
frame = toHSL(frame)
// Threshold, looking for pixels that match our expected range of color
frame = frame
.threshold(hueMin, satMin, lightMin, hueMax, satMax, lightMax)
// Find all of the blobs (contours) in the resultant image
contours = findContours(frame)
if contours.length() > 0 {
// Assume that the largest blob is the target
target = max(contours)
if screenCenter.x is inside target {
return true
}
}
return false
}
Considering that we knew nothing about vision processing before the two month preseason we prototyped this in, it wasn't bad progress. We had a lot of good ideas, and our algorithm was more or less solid for the goal we were trying to accomplish, but as usual, the real world gets in the way of even the most perfect algorithms. For example, the speed that our program ran on the roboRIO, was, shall we say, *lacking*. To be honest, our frame rate sucked, and the CPU hogging targeting thread interfered with normal robot operations during matches. This problem would only become more evident during real competitions, as the algorithm needed would be more complex. Additionally, despite making every effort to tune our threshold values, we still encountered noise here and there. This becomes a pretty big issue when you automatically assume that the largest contour in the image is your target. Going back to circumstances at real competitions, just knowing whether or not the target is centered isn't very helpful. We want to actually figure out where the target is in relation to our robot.
Still though, definitely good progress.
BinaryImage* Targeting::filterImage(ColorImage* inputImage)
{
//This should threshold for the green that was on Brian's shirt that night
//(roughly green, tweak this before testing)
return inputImage->ThresholdHSL(0,255,0,255,210,255);
}
A fun snippet from our preseason code :)
Stronghold (2016)
The real competition was here. No more time for jokes. Brian's shirt simply would not do for testing anymore. Especially because these days FIRST likes to use retroreflective tape for its targets! Evidently, they intend for teams to attach a light to their camera, but we didn't have a nice LED ring on hand, so we ended up just holding a flashlight near the camera for our initial tests.
{kind=link}
Speaking of initial tests (and the camera they were done with), we ended ditched the roboRIO and IP camera. Instead, we decided to run all of our code off a Raspberry Pi, using Java. Our solution was portable, wouldn't affect the main robot's performance, and through the wonders of Java, should in theory be very easy to test with on our own computers before deploying to the Pi. At this point, a USB camera seemed more economical, so we picked up a few cheap Logitech ones.
With this decision came a bit of extra legwork (networking between the roboRIO and Raspberry Pi) and a clear division of code between the pure image processing (done on the Pi) and actual aiming procedure (done on the RIO). Chris and I felt most comfortable working on code very similar to what we had already done during preseason, so we opted to focus on the Raspberry Pi image processing side of things. Brian (second-year programmer, owner of the green shirt) volunteered to work on networking (on both platforms), and Alice (second-year programmer, might own a green shirt, I'm not sure) took over the C++ aiming code.
As our three separate stories progressed through the season, we each began to encounter problems. Little ones at first, then big ones, and then before we knew it the season was over and vision just wasn't there. I'm getting a little bit ahead of myself here though, let's go through what happened from each perspective.
The Chris and I Story
Starting out the season optimistic, we got right to writing code. Java wasn't too difficult to use, since we were both currently enrolled in a Java class. After some cursory research, we chose webcam-capture and BoofCV as our libraries of choice, got our Java environments set up, and began.
The light we were using was white, which meant that when we shined it at the retroreflective target, it lit up... well... white. Our camera was using its default auto exposure setting, which meant that the target was SO bright that it overflowed the sensor. Essentially, the target would almost always show up as pure white (RGB 255, 255, 255) on our screen. The problem is, the exposure was (automatically) set so high that there were also a bunch of other things showing up with exactly the same color. The fluorescent lights all over the ceiling were the primary offender in our case. In reality, the target may have actually been brighter than the lights, but it was impossible to tell on our exposure settings. High exposure means you lose information.
Not knowing of a better way, we moved forward with our camera/light setup even with this problem. We opted not to convert from RGB to HSL, and instead just thresholded for high red/green/blue values. Pixels from 230, 230, 230- 255, 255, 255 ended up as white on our screen, and everything else black. Despite this rather strict threshold, we still ended up seeing a lot of noise (since really, anything white would get through).
This created a new challenge: how do you identify if a given shape is the target and not, for example, a light? This question stumped us. The solution we ended up going with simply involved looking for a shape that was very square. If we found one, we called it the target. Not fantastic, and it often picked up lights, even when an actual target was present.
Luckily for us, this didn't even matter very much, since we found out a few days before our competition that the Raspberry Pi had very serious problems running our code. Turns out with the resolution we were using, there was a 1-2 second latency getting each frame. Combined with a low overall framerate and issues correctly finding targets in the first place, our code was in no state to be used at a competition.
The Brian Story
In order for any of this to work, we needed to get to establish communications between the Raspberry Pi and the roboRIO. Early on, we decided that the Pi should only ever need to send data and the RIO would only ever need to receive. This simplified the problem a little bit, and after many long talks with mentors about the basics of networking (none of us students had a clue) Brian settled on writing a UDP client/server for our communications from scratch. After managing to send a few test packets from Java to C++, he ran into his first problem. Packets were being received, but they absolutely did not contain the values that they were supposed to. Looked like C++ and Java stored integers slightly differently (endianness), and that was messing everything up. I'm sure that for computer science majors, these 10-ish lines would be child's play, but for high school students? After much deliberation, he ended up with this code to convert 32-bit integers to bytes and back again.
Java (server):
public static byte[] intToByte(int num){
byte[] m_intToByteConvertBuf = new byte[4];
m_intToByteConvertBuf[0] = (byte) ((num & 0xff000000) >> 24);
m_intToByteConvertBuf[1] = (byte) ((num & 0xff0000) >> 16);
m_intToByteConvertBuf[2] = (byte) ((num & 0xff00) >> 8);
m_intToByteConvertBuf[3] = (byte) (num & 0xff);
return m_intToByteConvertBuf;
}
C++ (client):
void Client::byteToInt(char *byteArray, int *intArray){
int currentByte = 0;
for (int currentInt = 0; currentInt < sizeof(intArray); currentInt++) {
intArray[currentInt] = (int) byteArray[currentByte] +
(int (byteArray[currentByte+1] <<8);
currentByte+=2;
}
}
Worked beautifully. Of course, it did work beautifully. And then we flashed our radios to the competition firmware provided by FIRST and suddenly the firewall on the router completely killed the UDP connection. He never got it working with competition-ready radios.
The Alice Story
More our fault than hers, the best Chris and I ever managed to do was send pixel (yes, pixel) coordinates corners of the target back to the RIO. As for turning those pixel coordinates into an angle we could actually turn our drivetrain to, we were all stumped. Chris and I had something resembling an idea, relying on the concept that from the side, the top and bottom edges of the target should in 2D space appear to be at an angle, while when looking at it head on, they should be horizontal. We simply turn until the top and bottom edges are horizontal in the frame. If this doesn't make any sense to you, don't worry, it's not your fault. It wasn't really a very good idea.
Alice spent a couple of weeks implementing our "plan" on the RIO, ironing out bugs, etc. Unfortunately, turns out with a plan this terrible it doesn't really matter if your code is bug-free. When the time came for testing, whether it was because of bugs somewhere in the pipeline (like perhaps the infamous and never-resolved ceiling light problem) or simply flawed ideas, the automatic aiming code failed spectacularly.
Wrapping it up
On bag and tag day, our team had more or less decided not to use vision for any competitions. I can't be too upset though, because to be fair, it didn't work at all. We learned a lot, and would be back at it again next year. For interested parties, the code running on the Raspberry Pi can be found here and the code running on the RIO can be found somewhere on this branch of our 2016 robot code repository.
Steamworks (2016-2017)
Back at it next year... right. Chris left for CAD, Alice never wanted touch this awful project again, and Brian became code lead and suddenly had more important things to do (ha, nerd). I wanted to keep working on it though, and joined forces with James, who was now back from the PHP/SQL hell of writing a server for our scouting app last year.
Beginning with the camera, we switched to a green LED ring. The green light reflects off of the tape, making it appear green to the camera. This means that our algorithm can search for something both bright and green, instead of just something bright as were doing last year (using a white LED ring). We also turned down the camera's exposure. On the default settings, the the camera was capturing far too much light, coming close to maxing out some of the color registers. We want to make sure this never happens (information is lost when pixels hit their maximums or minimums), so we turn the exposure down a bunch.
 High exposure vs. low exposure
High exposure vs. low exposure
We hooked our camera up to NVIDIA's Jetson TK1, a board specifically designed for computer vision applications. It includes a significantly better processor than the Raspberry Pi we had previously, and has an on-board GPU. This time, we made a Concerted Effort to pick a language/library better suited for our goals (goodbye two second frame capture latency...). We ended up with OpenCV, a fantastic and well-supported computer vision library written in C, with wrappers in C++, Java, and Python! Pretty cool. Python immediately stood out to us, due to its ease of use and speed to program in. Now, I know what you're thinking: "Woah there, buddy. Python? Kiss your speed goodbye!" Ordinarily you would be right, but it's important to understand that OpenCV in Python is merely a wrapper around native code. As a result, calling OpenCV functions in Python doesn't incur much of a performance drop at all.
Python it is, then. After making the switch from Java, I would estimate my productivity went up several times over. Just a better suited language for the problem. We implemented some basic HSL based thresholding to look for a bright green target, and were surprised to see the target appear, crystal clear, in the center of the screen. With my experience from last year, we got this working in a single meeting. Certainly a breath of fresh air after all of the trouble we had last year.
 The thresholded image
The thresholded image
Now that we have an evenly exposed image and some threshold values which generally only pick up our target, the rest is almost trivial. With so little noise, we don't need any complicated tricks to figure out which two shapes in the picture represent our high goal target. That said, more precision never hurts :)
The obvious approach is to simply find the two largest contours (shapes) and call the convex hull around them the target, but we saw some edge cases where there were other objects in the frame being picked up that were big enough to cause problems. Particularly, this year's game uses neon green balls, which are incidentally both very bright and very very green. Our threshold didn't stand much of a chance. To prevent our algorithm from picking up the balls (or any other weird noise that ends up in the image) as the target, we attempted to find the two contours in the image which most looked like a target. If there weren't any two contours which looked enough like a target, we decide that the target is not in the image.
To achieve this, we take all length-2 permutations of the contours in the image and run a cost function on each combination. To avoid factorial time, we'll only look at the largest six contours in the frame, resulting in 15 (or fewer) combinations to look at every frame. In the case of the high goal, we say that a pair of contours has a low cost if they have a much lower horizontal offset than they do vertical offset. We then look for the pair with the lowest cost, since as long as your camera is horizontal, the two stripes on the goal should always be almost perfectly horizontally aligned.
def high_goal_cost(c1, c2):
# identify the centers of each contour
M1 = cv2.moments(c1)
cx1 = int(M1['m10'] / M1['m00'])
cy1 = int(M1['m01'] / M1['m00'])
M2 = cv2.moments(c2)
cx2 = int(M2['m10'] / M2['m00'])
cy2 = int(M2['m01'] / M2['m00'])
# calculate offsets
offset_x = abs(cx1 - cx2)
offset_y = abs(cy1 - cy2)
# offset_x is 6 times more important than offset_y (lower is better here!)
return offset_x * 6 + offset_y
Using this method, we pick the target out of the image successfully even if there's a bit of noise. None of the calculations are very expensive, so performance decrease is minimal, even operating on 15 different combinations of contours. With the first big problem solved, it's time to convert the pixel values representing our target to something actually useful.
Last year, we struggled with this problem a great deal. Chris and I had some idea that it could be accomplished with the field of view (FOV) and trigonometry, but weren't sure exactly how. More importantly, we had no idea what the field of view on our camera really was. We tried quite a few things to calculate the FOV, then use our calculated value to figure out angles, etc. It didn't quite work and we couldn't figure out the math to fix it, so we abandoned the idea.
Turns out that we were actually onto something. This year, we were able to find the diagonal FOV simply by looking at the specs sheet for our camera (haha hindsight really is 20/20 huh) and by the powers of James and I combined, we came up with a single constant which could turn any pixel value into the equivalent degree value.
# pixels to degrees
ptd = fov / math.sqrt(math.pow(res_x, 2) + math.pow(res_y, 2))
After that, calculating the horizontal and vertical angle of our camera in relation to the target was as simple as these two lines of code, where cx is x coordinate of the target center and cy is the y coordinate of the target center:
angle_x = ((res_x / 2) - cx) * ptd
# correct for the camera being tilted upwards
angle_y = ((res_y / 2) - cy) * ptd + config.CAMERA_ANGLE
But wait, there's more! Using more trigonometry, we can also calculate the horizontal distance along the ground from the camera to the boiler using only the real world height of the target, the angle_y we just calculated in the previous step, and the height of our camera off the ground!
distance = abs((high_goal_height - camera_height) / math.tan(math.radians(angle_y)))
Excellent. Using these values, our robot can turn to the correct angle in one smooth motion, spin the fly wheels up an appropriate amount based on our distance away, and then begin shooting. Just one problem... these values are all still on our coprocessor, not the roboRIO!
As with most of our problems, the answer was essentially right in front of us all along. FIRST seems to have anticipated the need for network communication already, and generously provides a network-based key-value store in in WPIlib. They call it NetworkTables. Using this class on the RIO naturally pretty simple, since WPIlib is already there and all set up. On the Jetson, we found a pure Python implementation of the NetworkTables protocol, included as part of the robotpy project (which I would highly recommend checking out, if you haven't already).
NetworkTables worked exactly as expected out of the box, and before we knew it, our angle and distance values were available on the RIO. At this point, all that was left to do was write some basic code to turn to the angle on the NetworkTable and spin up the fly wheels to the appropriate speed (based on the distance that our coprocessor calculated). Then we were good to shoot. Our TK1 coprocessor averaged about 10 frames per second running our program with close to zero latency retrieving frames, and that was without any GPU optimization. Not so bad, all things considered. Certainly a lot better than last year. Code is, of course, available here.
A quick demonstration of what our targeting system can do. Since actually moving the target requires getting up, you can observe the change in distance with angle just by tilting the camera up and down. When the target is further away, it will be lower in the frame, and distance will decrease.Addendum: Gear Targeting
After our first competition (and after I thought I was done writing this section), it became all too clear that vision for placing gears would be extremely helpful, both for autonomous and teleop. For me and James, that meant that it was really crunch time. We had prototyped some basic gear vision stuff earlier in the season, but decided to focus on high goal.
The most important difference between the gear vision problem and the high goal vision problem is that the gear vision target doesn't look the same from all sides. This means that we get to use OpenCV's built-in (and basically witchcraft) pose estimation algorithm! By feeding it the pixel coordinates of our target (image points), an arJames representing what the target looks like in real life (object points), and some properties of our camera (distortion and camera matrices, see here), it calculates the 3D position of the target relative to the camera. This is kind of similar to what we did by hand for the high goal, but it gives us much more detailed information. In our case, we use it to to fill in values for our three step gear placement process:
- Rotate to be parallel to the peg
- Move sideways until the peg is directly in front of us
- Move forwards until the gear is on the peg
OpenCV's function doesn't give us rotation in a very easy to use form, so we have to do a little bit of math to get the rotation value we want. Other than that, pretty straightforward stuff.
# witchcraft
rvecs, tvecs = cv2.solvePnP(gears_objp, imgp, mtx, dist)
# calculate the rotation in radians on the y axis (left/right)
R, _ = cv2.Rodrigues(rvecs)
sy = math.sqrt(R[0, 0] * R[0, 0] + R[1, 0] * R[1, 0])
y = math.atan2(-R[2, 0], sy)
# final values for our movement, in degrees/inches!
rotation = y / math.pi * 180
horizontal = -float(tvecs[0])
forward = float(tvecs[2])
Conclusions
Over this 1.5 year period, I feel that I, personally, and my team learned a lot about what accomplishing a machine vision based strategy really involves. It certainly isn't easy to do reliably, and with almost no mentor assistance took quite a while to figure out. That said, this year should be the beginning of a long series of machine vision strategies in the future for Team Phoenix. There are certainly a few things to consider for next time, which I'd like to take a moment to list now:
- GPU optimization on the coprocessor. As it currently stands, everything is being done on the CPU, not making use of what's essentially the whole point of the Jetson series: the GPU. We get an okay framerate doing things this way, but perhaps in the future we can increase it even further by utilizing the GPU.
- The Pixy Camera, which automatically tunes thresholds and picks contours out of images for you. It's easily trained on any object, and may be a faster and more reliable solution than doing this step manually.
- Using an even smarter method to identify targets. I'm thinking neural networks. We'll see if I can make it happen for next year :)
I will say, it certainly felt quite satisfying to almost fully solve the vision problem after such a long time working on it. Maybe it will finally put to rest the meme about vision not working...
*sigh*
Yours,
Stephan